检索增强生成 (RAG)
RAG 使您的应用程序能够引用和回忆来自先前交互或外部文档的信息。
Llama Stack 将实现 RAG 的 API 分为三个层次
最底层的 API 处理原始存储和检索。这些包括 Vector IO、KeyValue IO(即将推出)和 Relational IO(也即将推出)。
接下来是“Rag Tool”,它是 Tools API 的一个一等工具,允许您以各种分块策略摄取文档(来自 URL、文件等)并智能地查询它们。
最后,这一切都通过顶层的 “Agents” API 汇集在一起,该 API 允许您创建能够使用这些工具回答问题、执行任务等。
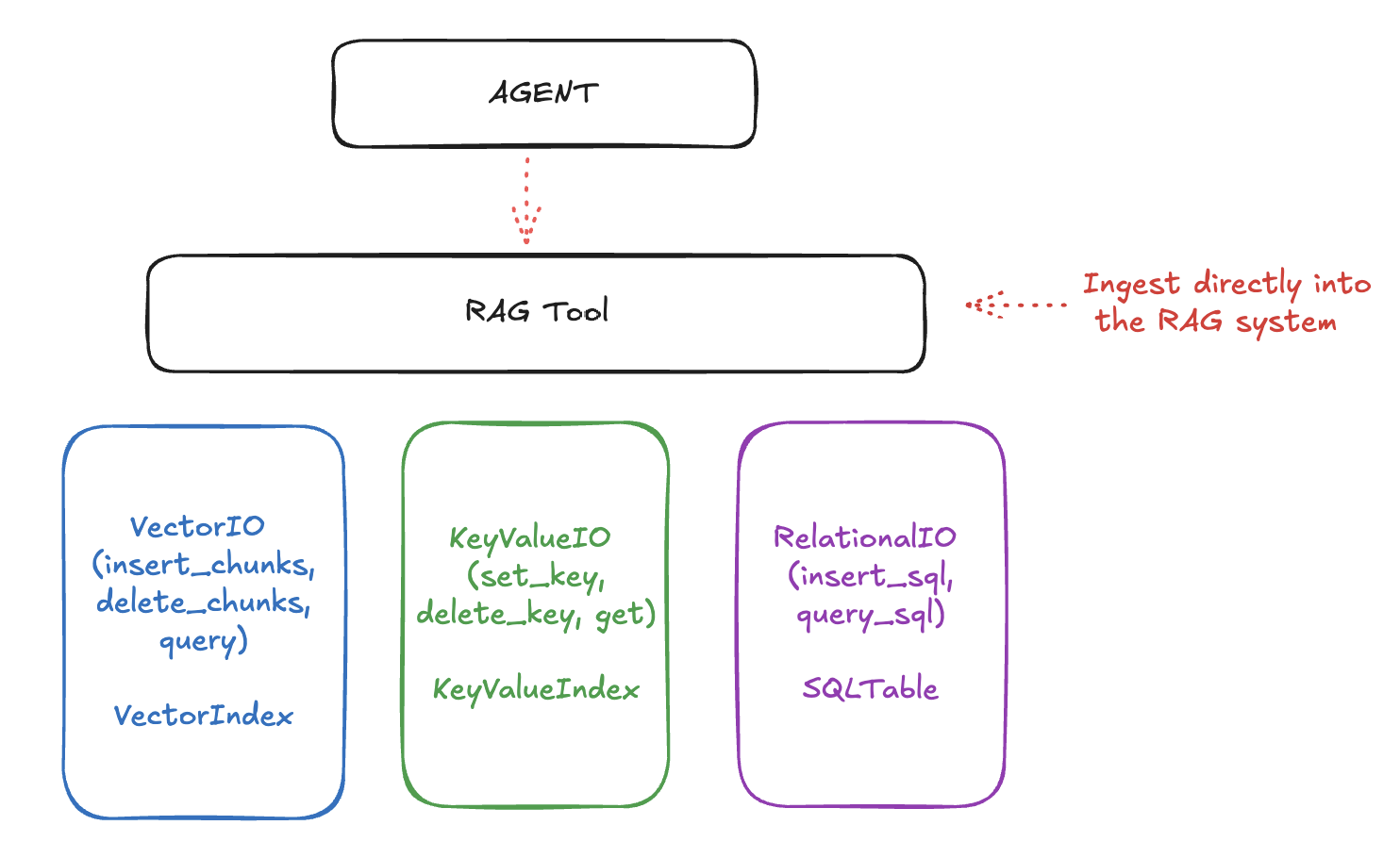
RAG 系统使用较低层存储不同类型的数据
Vector IO: 用于语义搜索和检索
Key-Value and Relational IO: 用于结构化数据存储
未来我们可能会添加更多存储类型,例如 Graph IO。
设置向量数据库
本指南将使用 Ollama 作为推理提供者。Ollama 是一个 LLM 运行时,允许您在本地运行 Llama 模型。
以下是如何设置向量数据库以用于 RAG
# Create http client
import os
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url=f"https://:{os.environ['LLAMA_STACK_PORT']}")
# Register a vector db
vector_db_id = "my_documents"
response = client.vector_dbs.register(
vector_db_id=vector_db_id,
embedding_model="all-MiniLM-L6-v2",
embedding_dimension=384,
provider_id="faiss",
)
文档摄取
您可以通过两种方法将文档摄取到向量数据库中:直接插入预分块文档或使用 RAG 工具。
# You can insert a pre-chunked document directly into the vector db
chunks = [
{
"content": "Your document text here",
"mime_type": "text/plain",
"metadata": {
"document_id": "doc1",
"author": "Jane Doe",
},
},
]
client.vector_io.insert(vector_db_id=vector_db_id, chunks=chunks)
检索
您可以查询向量数据库以根据其嵌入向量检索文档。
# You can then query for these chunks
chunks_response = client.vector_io.query(
vector_db_id=vector_db_id, query="What do you know about..."
)
使用 RAG 工具
摄取文档的更好方法是使用 RAG 工具。该工具允许您摄取来自 URL、文件等的文档,并自动将其分块。有关如何格式化 RAGDocument 的更多示例可在附录中找到。
from llama_stack_client import RAGDocument
urls = ["memory_optimizations.rst", "chat.rst", "llama3.rst"]
documents = [
RAGDocument(
document_id=f"num-{i}",
content=f"https://raw.githubusercontent.com/pytorch/torchtune/main/docs/source/tutorials/{url}",
mime_type="text/plain",
metadata={},
)
for i, url in enumerate(urls)
]
client.tool_runtime.rag_tool.insert(
documents=documents,
vector_db_id=vector_db_id,
chunk_size_in_tokens=512,
)
# Query documents
results = client.tool_runtime.rag_tool.query(
vector_db_ids=[vector_db_id],
content="What do you know about...",
)
如果您认为对您的应用程序有用,可以配置 RAG 工具如何将元数据添加到上下文中。只需添加
# Query documents
results = client.tool_runtime.rag_tool.query(
vector_db_ids=[vector_db_id],
content="What do you know about...",
query_config={
"chunk_template": "Result {index}\nContent: {chunk.content}\nMetadata: {metadata}\n",
},
)
构建 RAG 增强型代理
最强大的模式之一是将代理与 RAG 能力结合起来。这是一个完整的示例
from llama_stack_client import Agent
# Create agent with memory
agent = Agent(
client,
model="meta-llama/Llama-3.3-70B-Instruct",
instructions="You are a helpful assistant",
tools=[
{
"name": "builtin::rag/knowledge_search",
"args": {
"vector_db_ids": [vector_db_id],
# Defaults
"query_config": {
"chunk_size_in_tokens": 512,
"chunk_overlap_in_tokens": 0,
"chunk_template": "Result {index}\nContent: {chunk.content}\nMetadata: {metadata}\n",
},
},
}
],
)
session_id = agent.create_session("rag_session")
# Ask questions about documents in the vector db, and the agent will query the db to answer the question.
response = agent.create_turn(
messages=[{"role": "user", "content": "How to optimize memory in PyTorch?"}],
session_id=session_id,
)
注意:
AgentConfig中的instructions字段可用于指导代理的行为。尝试使用不同的指令来找出最适合您的用例的方法非常重要。
您也可以在用户消息中附带文档,并询问有关这些文档的问题。
# Initial document ingestion
response = agent.create_turn(
messages=[
{"role": "user", "content": "I am providing some documents for reference."}
],
documents=[
{
"content": "https://raw.githubusercontent.com/pytorch/torchtune/main/docs/source/tutorials/memory_optimizations.rst",
"mime_type": "text/plain",
}
],
session_id=session_id,
)
# Query with RAG
response = agent.create_turn(
messages=[{"role": "user", "content": "What are the key topics in the documents?"}],
session_id=session_id,
)
您可以使用以下方法打印响应。
from llama_stack_client import AgentEventLogger
for log in AgentEventLogger().log(response):
log.print()
取消注册向量数据库
如果您需要清理并取消注册向量数据库,可以按如下方式进行操作
# Unregister a specified vector database
vector_db_id = "my_vector_db_id"
print(f"Unregistering vector database: {vector_db_id}")
client.vector_dbs.unregister(vector_db_id=vector_db_id)
# Unregister all vector databases
for vector_db_id in client.vector_dbs.list():
print(f"Unregistering vector database: {vector_db_id.identifier}")
client.vector_dbs.unregister(vector_db_id=vector_db_id.identifier)
附录
更多 RAGDocument 示例
from llama_stack_client import RAGDocument
import base64
RAGDocument(document_id="num-0", content={"uri": "file://path/to/file"})
RAGDocument(document_id="num-1", content="plain text")
RAGDocument(
document_id="num-2",
content={
"type": "text",
"text": "plain text input",
}, # for inputs that should be treated as text explicitly
)
RAGDocument(
document_id="num-3",
content={
"type": "image",
"image": {"url": {"uri": "https://mywebsite.com/image.jpg"}},
},
)
B64_ENCODED_IMAGE = base64.b64encode(
requests.get(
"https://raw.githubusercontent.com/meta-llama/llama-stack/refs/heads/main/docs/_static/llama-stack.png"
).content
)
RAGDocuemnt(
document_id="num-4",
content={"type": "image", "image": {"data": B64_ENCODED_IMAGE}},
)
如需更强的类型交互,请使用 此处 的类型化字典。